
 (Illustration by Hugo Herrera)
(Illustration by Hugo Herrera)
In 2021, US companies generated $2.77 trillion in profits—the largest ever recorded in history. This is a significant increase since 2000 when corporate profits totaled $786 billion. Social progress, on the other hand, shows a very different picture. From 2000 to 2021, progress on the United Nations Sustainable Development Goals has been anemic, registering less than 10 percent growth over 20 years.
What explains this massive split between the corporate and the social sectors? One explanation could be the role of data. In other words, companies are benefiting from a culture of using data to make decisions. Some refer to this as the “data divide”—the increasing gap between the use of data to maximize profit and the use of data to solve social problems.
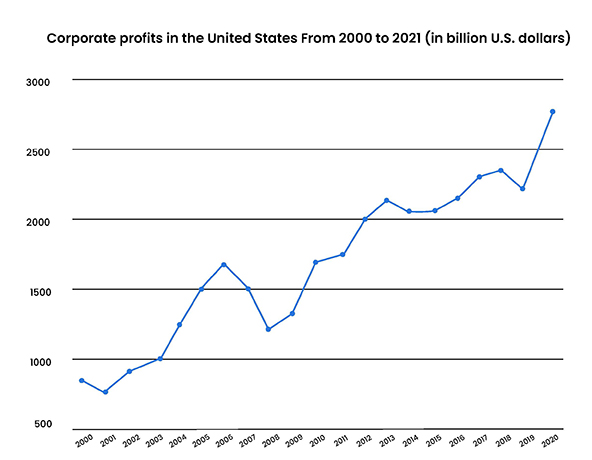 (Sources: BEA, Statista)
(Sources: BEA, Statista)
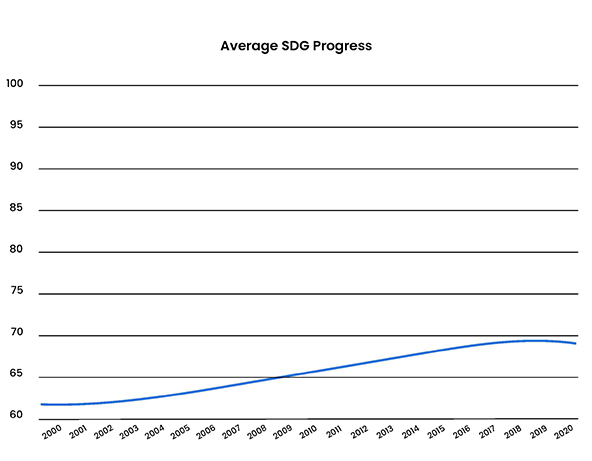 (Source: United Nations)
(Source: United Nations)

According to a survey commissioned by IBM in 2022, 77 percent of companies reported they were already using artificial intelligence or were exploring how to use artificial intelligence in their business. In contrast, a 2017 report found that only 5 percent of nonprofits were using artificial intelligence, and only 28 percent of nonprofits were using data for predictive or prescriptive purposes. The public sector isn’t much different. While government agencies worldwide face enormous challenges in leveraging their data to deliver services effectively and efficiently, 89 percent of public sector respondents in 2020 said they were unprepared for rapid data growth.
The fact is, we are in a transformative era where the speed of technological advances and exponential data growth has already changed how we work and live. Thus, it is highly plausible that this data divide between the corporate and social sectors could be a key differentiator in overall progress. The same 2017 survey of nonprofits conducted by IBM found that 78 percent of nonprofits with advanced analytics capabilities reported higher effectiveness in performing their missions.
So, if there is such an obvious correlation between data and progress, why aren’t more nonprofits and social sector organizations using data?
Early research to understand the lack of data adoption has primarily focused on the organizational level. This important work has uncovered real barriers: lack of investment capital, lack of internal capacity, cultural barriers, lack of technology innovation, limited access to data scientists, and more. According to IBM’s research, “While these [budget, technology, and talent] barriers are common across sectors, nuances of the nonprofit industry intensify the effects. In the private sector, market forces drive investment in data to stay competitive. Conversely, nonprofits struggle with raising funds for what is considered internal overhead investments, as funding is often restricted to programmatic activities.”
There have been efforts to overcome some of these barriers. We identified 115 different initiatives under the name “data for good” or “AI for good,” and there are probably many more initiatives afoot in the wake of ChatGPT. Many nonprofits can now access free versions of software tools from myriad companies small and large through charitable initiatives of those companies. Intermediaries like TechSoup also offer free or reduced-cost access to hundreds of products and organizations like DataKind and Data.org exist to make data science talent more accessible to nonprofits. Yet these initiatives are not enough and only solve a piece of the overall challenge.
Our theory is that there is something more systemic going on. Even if nonprofit practitioners and policy makers had the budget, capacity, and cultural appetite to use data; does the data they need even exist in the form they need it? We submit that the answer to this question is a resounding no. Usable data doesn’t yet exist for the sector because the sector lacks a fully functioning data ecosystem to create, analyze, and use data at the same level of effectiveness as the commercial sector.
Anatomy of a Data Ecosystem
Data ecosystems exist in many fields: finance, health care, retail, entertainment, elections, and even sports. In each of these industries, outcomes data is collected, standardized, synthesized, benchmarked, and used to inform predictive models. For example, Pandora (music streaming) tracks outcomes data on what songs people choose. Target tracks outcomes data on what things people buy. 23andme uses DNA and user input to help researchers link genetic traits to disease. Bloomberg tracks financial outcomes data on corporate performance. And so on.
Before going any further, we do want to caution that the commercial data ecosystem, left unregulated, has led to negative consequences, especially for marginalized groups. Access to vast amounts of private, personalized information demands careful regulation and control. Data ethics has even more heightened sensitivity in the public and nonprofit sectors, where trust is essential to an organization’s license to operate. Despite the ethical pitfalls of the commercial sector, there are still important mechanisms of the data ecosystem that are worth leveraging to drive positive social and environmental outcomes.
Let’s take a look at the key mechanics behind commercial data ecosystems. While data ecosystems have evolved over time, there are four key levels of data processing:
Production-level data. The first level of the ecosystem is primary-level data production—in other words, raw data from the use of any product, service, experience, or intervention. This is individual-level transactional data, such as click rates, sales, grocery store scanner data, inventory levels, participation rates, subscription rates, admission rates, return rates, etc. This data might also include behavior data such as past purchasing behavior, loyalty, frequency of use, and other modalities. Most of this data lives inside small businesses, merchants, or software apps.
Platform-level data. The next level of the data ecosystem is where data is collected at scale. This level is dominated by large platform players. In the “old days,” big banks and credit card companies tracked transaction data for large masses of consumers. Now, with the advent of the internet and cloud computing, companies like Netflix, Nielsen, Google, Apple, Amazon, Meta, LinkedIn, Zillow, Spotify, and Tiktok are sitting on piles of highly structured, longitudinal data on user behavior.
Refinery and aggregation. Data refineries, aggregators, or brokers operating at this level are almost exclusively digital businesses and are designed to sell data to other businesses. These businesses collect and aggregate highly structured user data from platform players, and clean the data to combine it in ways that make it useful to researchers, marketers, political campaigns, credit bureaus, and others. The three major credit bureaus (Experian, Equifax, and TransUnion), for example, operate at this level, ingesting data from credit card issuers, mortgage companies, student loan servicers, and other sources to develop meta-data such as credit scores. This is where the commercial sector has behaved badly in terms of the ethical use of this highly personalized user data. And where the social and environmental sectors should—and will—do better.
Decision support. The top level of the data ecosystem is the realm of ratings agencies, recommendation engines, predictors, matching algorithms, and artificial intelligence. Companies at this level offer tools that apply data to real-world scenarios to answer questions. On the simple end, think X EXAMPLE, while the now-famous ChatGPT, by OpenAI, is probably the most audacious example of decision-support use cases. Decision support systems are crucial to the data ecosystem because these tools synthesize vast amounts of unstructured data and make it actionable for decision makers.
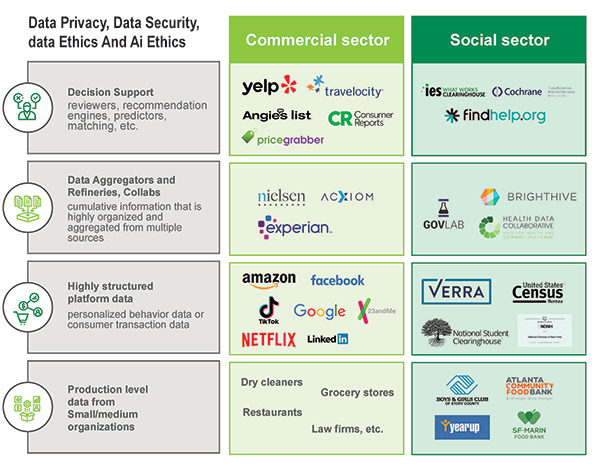
Mature data ecosystems work because each layer of the data is part of a “supply chain” that builds on the one below. Every level has a distinct economic purpose and a clear value-add. And most fundamentally, the data ecosystem works because the data is highly structured and fungible, making it easy to aggregate and synthesize.
Analyzing the Data Divide: What’s Missing?
Data plays a fundamentally different role in the social sector. To better understand the determinants of the data divide, we conducted interviews with data scientists, economists, nonprofit practitioners, philanthropists, evaluators, and policy makers. The research yielded a picture of a data ecosystem that has evolved largely based on compliance requirements as opposed to innovation and impact opportunity. We identified several key factors that have shaped the current state of the social impact data landscape.
- There are few dominant or widely-used data platforms in the social sector. Nonprofit organizations use a wide variety of home-grown or boutique software platforms, limiting the value added (and also risks) of large commercial data platforms. Government agencies also typically hire contractors to build customized software and therefore collect data idiosyncratically. Many of the grant management systems and case management software are “closed” without easily accessible interfaces, further limiting external data sharing. As a result, there is a high degree of fragmentation of data and a lack of data portability.
- Social impact data is not structured. Currently, outcomes data (information about the impact of social programs on individuals) is not standardized by any federal regulations, information intermediaries, or impact groups. Much of the impact data is driven by differentiated grant reporting requirements of government agencies, foundations, or donors. Even at the state and federal level, government agencies typically set their own internal performance goals—typically output measures—and report that data back to their respective executive offices of management and budget.
- Advanced use cases are underdeveloped. Due to the siloing of data, and the lack of structured impact data, there is limited investment in new technologies and predictive analytic data capabilities. As a result, there are few decision-support tools like recommendation engines, predictive algorithms, and the like. According to Stefaan Verhulst, cofounder, and chief research and development officer of The Governance Laboratory at New York University, “The real challenge is how do we make this [impact data] systematic, sustainable and responsible. Data collaborations, pilots, and one-off projects don’t scale. We need a new generation of people who can be data aggregators or collectors—we need a ‘chief data steward’ association.”
- Funding programs that work are not closely linked to impact. Contrary to the private sector, impact data (i.e. positive results) does not generate an immediate financial benefit that enables the organization to grow and drive more impact. As a consequence, data has not been highly valued in the social sector. According to one leading philanthropy executive, we interviewed: “There must be a financial benefit in demonstrating that data will help you target your intervention better, save more money, help more people, etc. If a higher impact rating generates more revenues and serves as an effective fundraising tool, then impact data will have value.”
- Absence of large-scale data platforms refineries. Our research found that the biggest “crack” in the data divide stems from the absence of large-scale data refineries in the social sector. There have been early efforts at refining social sector data, such as ad hoc data collaboratives, evidence bases, “what works” clearinghouses, financial databases, and rating agencies. But these efforts are piecemeal, underfunded, and typically not powerful enough to support the field on an ongoing basis.
The power behind data refineries lies in the way they structure, classify, and standardize data. These classifiers are called taxonomies. Why are taxonomies so important? Because data without taxonomies is kind of like Jell-O—without a mold, it’s just a mess.
Narrowing the Data Divide
Developing a social impact data ecosystem won’t happen overnight, but there are progressive steps we can take. Some of the progress will need to be on the “supply” side—creating better taxonomies, ontologies, data standardization, and shared databases. Other progress will need to come on the “demand” side—creating financial incentives, funding for innovation, and proving out new use cases. Here are three things we can do right now to begin bridging the data divide:
Innovation
First and foremost, we as a field need to create more structured impact data. While there is a lot of “data”—most of this data is administrative in nature. Structured data relating to the design, implementation, and outcomes of social programs is lacking. To solve this we need to attract entrepreneurs, researchers, and technologists who can invent new ways to make data more refined and more accessible. Some of the opportunities for innovation relate to structuring existing unstructured data such as research studies, evaluations, grant reports, grant applications, and program descriptions. Other opportunities for innovation might involve new ways of originating structured data from beneficiaries, practitioners, and funders.
One example of innovating structured data is the Justice Data Lab, a facility within the Ministry of Justice in the UK. It helps organizations working to reduce prisoner recidivism access government reoffending data so they can evaluate the impact of their intervention. Organizations can send their results data to the Lab, and a team of trained evaluators will compare the outcome variables submitted to a matched control group who did not receive the same intervention. This creates an instant “randomized evaluation” for any social intervention and acts as a mini data refinery for the service provider.
Another example is the Impact Genome Registry, an initiative pioneered by one of us (Jason). The Impact Registry allows any nonprofit to self-report their impact data to a centralized clearinghouse and have that data standardized and independently verified. The Impact Registry is currently being used by funders to verify the impact of their grants, by policy makers to design more effective social interventions, and by nonprofits to benchmark their results.
Other examples of developing high-value structured datasets include projects like USA Facts which collects and structures data on all US government spending, and the What Works Clearinghouse at the Institute for Educational Sciences, which codes evaluation studies on the effectiveness of education interventions.
Incentives
Data thrives on demand. In the commercial sector, the profit motive organically drives companies to seek refined, actionable impact data. In the social sector, there is no built-in system of financial rewards for impact. So better data does not equate to more revenue. But that can be changed by policy makers, innovators, and influential funders.
The most direct incentive is a financial reward for impact. In 2004, the first major “pay for outcomes” incentive was born when the Ansari XPRIZE awarded $10 million (then, the largest prize in history) to anyone who could achieve the outcome of building a reusable manned spaceship capable of going into space twice within two weeks. Since then, other prize competitions have directly linked cash to outcomes. The whole “pay for performance” movement, including social impact bonds and other innovative finance builds on this same incentive structure. The more direct the link between financial rewards and impact, the more the demand will grow for data and data refineries.
The same principle applies to academic research. Research remains the biggest treasure trove of “data”—yet every published article is published in an unstructured format, without the use of any impact taxonomies. This limits the potential for studies to be coded, synthesized, and aggregated into a data refinery. As a result, the field remains content with Boolean searches for literature reviews and compiling “evidence bases” that consist of PDF articles. Changing professional incentives for academic tenure could influence the demand for data refineries.
Investment
Lastly, the large resource allocators in the field—federal agencies, private philanthropies, and corporations—need to shift the way they invest in impact. First, we need to honor the importance of organizational effectiveness and invest in funding data capacity. Second, the field needs large infusions of capital to fund R&D, innovations, and new technologies. This is a call to action for private and public funding. In 1958, the government founded the Defense Advanced Research Projects Agency (DARPA) as an R&D arm for the military. What about creating a “DARPA” for education, health, and the environment? Third, we need to switch our mindset from funding projects to funding perpetuity for foundational systems that will benefit the entire sector, like impact data refineries. The goal of impact data refineries is to level the playing field so that all organizations have access to data that can help further their mission. Data, data skills, and data insights should not be accessible to only large organizations with big budgets.
Data is power. By closing the data divide, we can empower mission-driven organizations to innovate, access capital, and meet customer or beneficiary needs. We often say that our field of social impact does not have a resource problem, we have a resource allocation problem (as it is, social spending currently makes up 20 percent of GDP on average across the OECD). In other words, because we don’t have a structured impact data refinery, policy makers, funders, and practitioners have to guess what works. Commercial actors maximize the returns on their capital investments by using data to minimize the risk of failure; it’s time the social sector does the same.
Support SSIR’s coverage of cross-sector solutions to global challenges.
Help us further the reach of innovative ideas. Donate today.
Read more stories by Jason Saul & Kriss Deiglmeier.