

In a recent SSIR blog post, “Cracking the Code on Social Impact,” one of us (Jason Saul) introduced our Universal Outcomes Taxonomy, which serves as a foundation for benchmarking across the social sector. Even though this is a big step forward, the critical question remains: How can we benchmark social impact programs if they have no outcomes data?
The fact is that few nonprofits have quality outcomes data today, and they likely never will; capacity, cost, time, and consistency are all factors that make it impractical to expect them to produce quality data. To overcome this challenge, we must flip the measurement paradigm from empirical, longitudinal, retrospective data to real-time, predictive, algorithm-based data. In a word, we need to create “synthetic” data.
Other sectors have been successful in using algorithm-based data to predict future behavior or outcomes. For example, when someone applies for a loan, the bank uses his or her credit score to predict the likelihood of repayment. When a student applies to a college program, the admissions committee uses a formula that considers standardized tests, high school transcripts, and other factors to predict the likelihood that the student will be successful in the program. Both of these widely used and well-regarded decision-making tools rely on “synthetic” data.
The basis of developing this “synthetic” data is a comprehensive mapping of the factors involved in predicting a specific outcome. In 1990, the Department of Energy and the National Institutes of Health launched the Human Genome Project to predict health outcomes. In 2000, Pandora created the Music Genome Project to quantify music and predict songs that are likely to produce the outcome of a heightened listening experience. And now, in 2014, we’re announcing the launch of the Impact Genome Project, a massive effort to systematically codify and quantify the factors that research has shown drive outcomes across the entire social sector.
The fundamental idea behind the impact genome is that we can fully express the set of characteristics that describe any given social impact program. The systematic process we undertake to evaluate a program against the impact genome considers information based on a program’s operation, its theory of change, its outcome potential, and other metrics and indicators. By mapping all of these factors and comparing success across programs, we can leverage predictive analytics to forecast a program’s efficacy in producing a desired outcome.
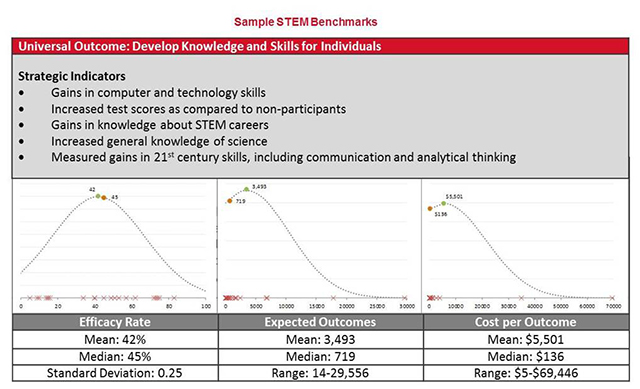
One example of how this approach works is an analysis of social impact programs focused on science, technology, engineering, and mathematics (STEM). These programs range widely in scope and include advocacy efforts, after-school enrichment, professional development, competitions, mobile museums, scholarships, career guidance, curriculum development, and science fairs. Although these programs are obviously quite different, we can compare them based on their contribution to enhancing an individual’s ability to understand and apply STEM-related knowledge and skills. In our taxonomy of standard outcomes, we call that ability “Developing Knowledge and Skills for Individuals.”
The impact genome for STEM leverages an analytical model that uses proven success factors to generate useful data for decision-making. This information includes metrics such as efficacy rate (the expected likelihood that a program will achieve an outcome), expected outcomes (the total number of people served by a program who are likely to achieve the intended outcome), and cost per outcome (the average expected cost for a program to achieve a “unit” of intended outcome).
The figure below is an example of findings derived from this process. Using the impact genome, we can evaluate a new STEM program and predict the program’s efficiency and effectiveness with confidence. It is also finally possible to compare performance across a set of programs that aim to produce the same outcome. In that way, we can understand the progress we are making on a broad scale.
Work on the STEM genome is just the beginning, and we are rapidly building out other areas of the impact genome (such as workforce development, arts, and housing) to create a comprehensive system that channels the power of data across every social impact area. The ultimate goal is to use these data so that funders—including governments, foundations, nonprofits, corporations, and individuals—can more effectively invest in social change and finally solve some of the world’s most intractable problems. It is possible. All we need are better data. Please join us in this exciting work!
Read more stories by Matt Groch & Jason Saul.