

Over the past few decades, practitioners, evaluators, and academics have struggled to organize, measure, and understand social change. We have made a number of important advances, including more rigorous control studies, digitization of 990 data, outcomes tracking software, and improved reporting. One important challenge evaluators have faced in the social sector is standardization: How can we learn from past efforts if we cannot systematically compare one socially focused program to another? Researchers have tried to solve the “apples to oranges” problem in a number of ways. In the 1980s, the Urban Institute’s National Center on Charitable Statistics (NCCS) created a common code for classifying nonprofit organizations by entity type, and later created another system to classify program services and beneficiaries. Others have tried to standardize performance metrics using “shared measurement systems” such as IRIS and the Cultural Data Project. Still, these efforts fall short of codifying the true results of an organization’s programmatic efforts: outcomes.
While much of the focus on outcomes has centered on trying to measure them idiosyncratically, one organization at a time, I believe—and our work at Mission Measurement is demonstrating—that the real value is in standardizing the use of outcomes for the whole sector. Here’s why this approach works:
- First, standardizing outcomes enables us to organize and identify social programs in a more meaningful way. Instead of researching programs based on subject area (for example, education, youth development, or the arts), we can base research on the benefits programs aim to produce (for example, improving college readiness, increasing access to public services and supports, or encouraging artistic expression).
- Second, common outcomes create a universal common denominator for benchmarking and comparison—something the sector has long sought. So we can now apply measures such as cost per outcome and social return on investment, and we can do this on an ever-increasing scale, as we standardize and universally adopt efficacy rates.
- Finally, program design and learning is much more efficient. Researchers can more easily identify program elements that increase efficacy and cross-sector synergies that conspire to produce outcomes.
My thinking about this approach to measurement—what I call “universal outcomes taxonomy”—dates back to my 2004 book Benchmarking for Nonprofits and a subsequent effort I led at the Urban Institute and the Center for What Works to create a prototype for classifying social outcomes. Since then, we have carefully documented more than 78,000 outcome data points (78,369 to be exact) from more than 5,800 social programs. Two years ago, we focused a team of researchers on the daunting task of systematically cataloguing those outcomes—removing duplicates, standardizing language, creating hierarchies, and developing a universal taxonomy. Not surprisingly, we found that many of the outcomes were the same, though articulated differently. For example, one organization might state its objective as “student achievement,” another as “academic achievement,” and another as “improving test scores.” In all, we identified 132 common outcomes across the entire social sector. We then indexed these outcomes by program type and sub-type, and classified them into a functional taxonomy (see below). We also added geo-coding and beneficiary codes to better contextualize outcomes.
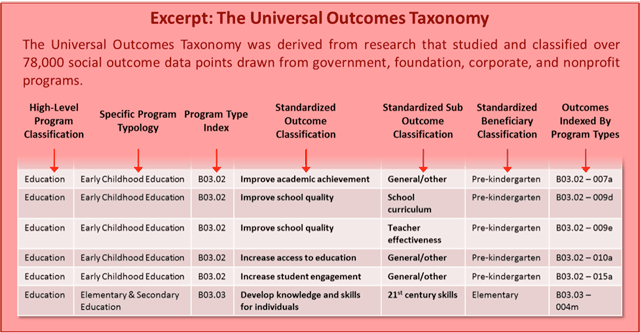
But while it is becoming clearer what value-seeking funders want, the problem remains that we still face a number of barriers to producing these data.
Today, a growing number of funders across the country are using this framework to organize, or “tag,” their grants and programs, making it possible to analyze their work on a portfolio level. They can measure the resources they have allocated to each outcome and the relative contribution of each program to a particular outcome, and aggregate the overall performance of the portfolio.
We believe that this new language holds great promise for the sector, and we have much work to do. First, we must enable widespread adoption of the taxonomy—by both funders and social service providers. Second, we need to build the capacity of organizations to select the right outcomes (what we call “sizing the outcomes”). And finally, we must continually curate and improve the taxonomy, with feedback from practitioners and researchers.
Read more stories by Jason Saul.